Jenkins X 初体验
前言
Jenkins X 是一个高度集成化的CI/CD平台,基于Jenkins和Kubernetes实现,旨在解决微服务体系架构下的云原生应用的持续交付的问题,简化整个云原生应用的开发、运行和部署过程。
官方链接: http://jenkins-x.io/
安装(for macOS)
install Jenkins X with brew
brew tap jenkins-x/jx brew install jx

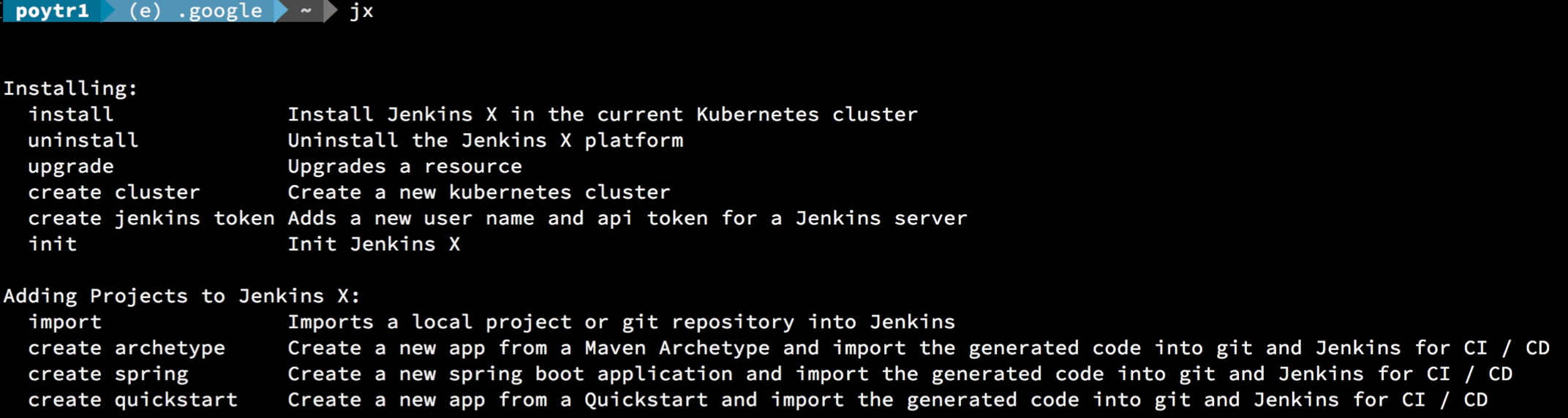
输入 jx 应该能看到如下输出
create local cluster for test
jx create cluster minikube
这个过程比较长,有几个步骤
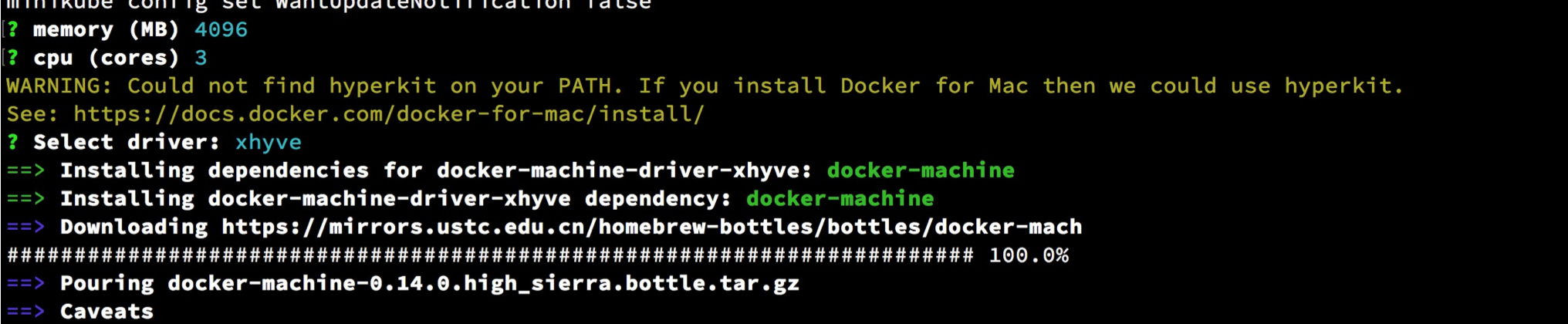
为 minikube 分配内存、CPU、driver
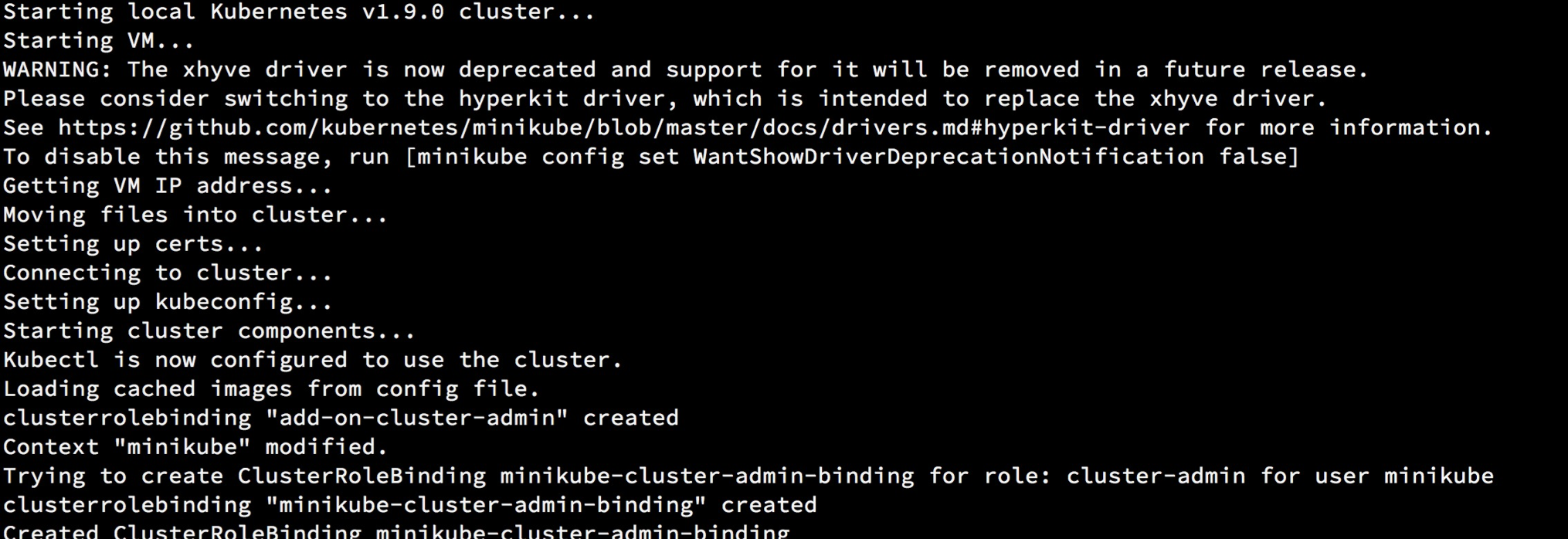
之后会下载 minikube 的镜像与 localKube 的 binary,并启动 kubernetes, 设置 RBAC
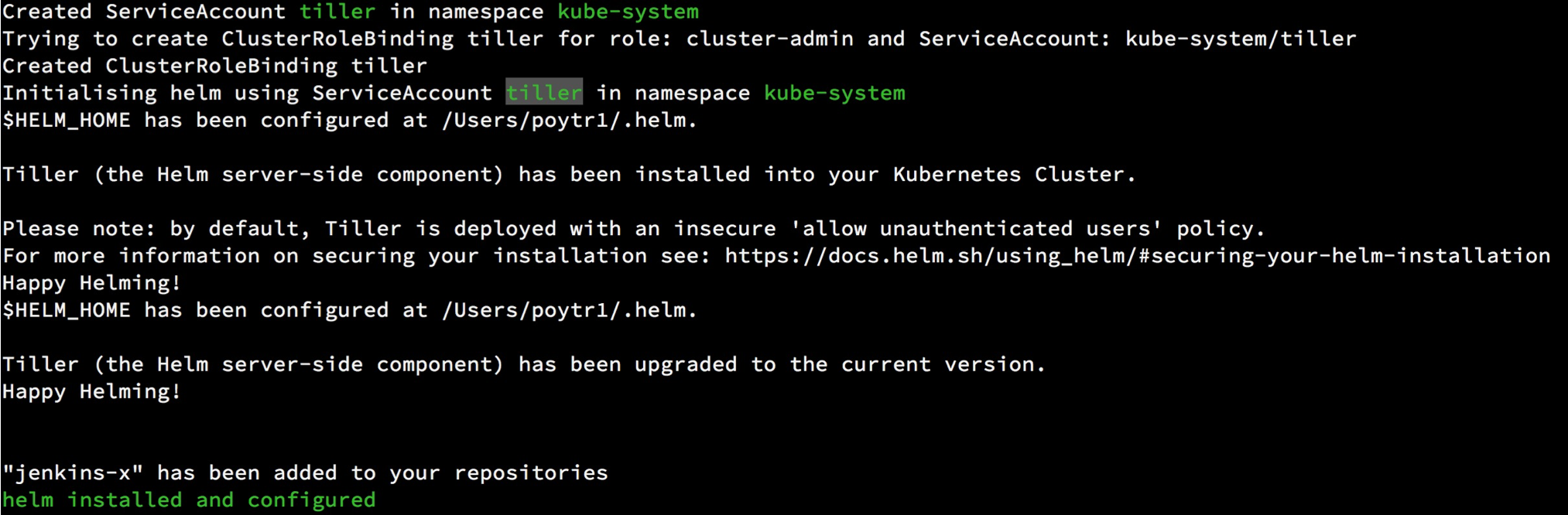
jx 使用 helm 来管理 kubernetes 上的应用,所以会在 k8s 上初始 helm 的 server(tiller)。
安装 NGINX Ingress Controller

设置 Github 的 API Token,点击生成的 URL,生成一个 API Token

设置 Jenkins 的 API Token
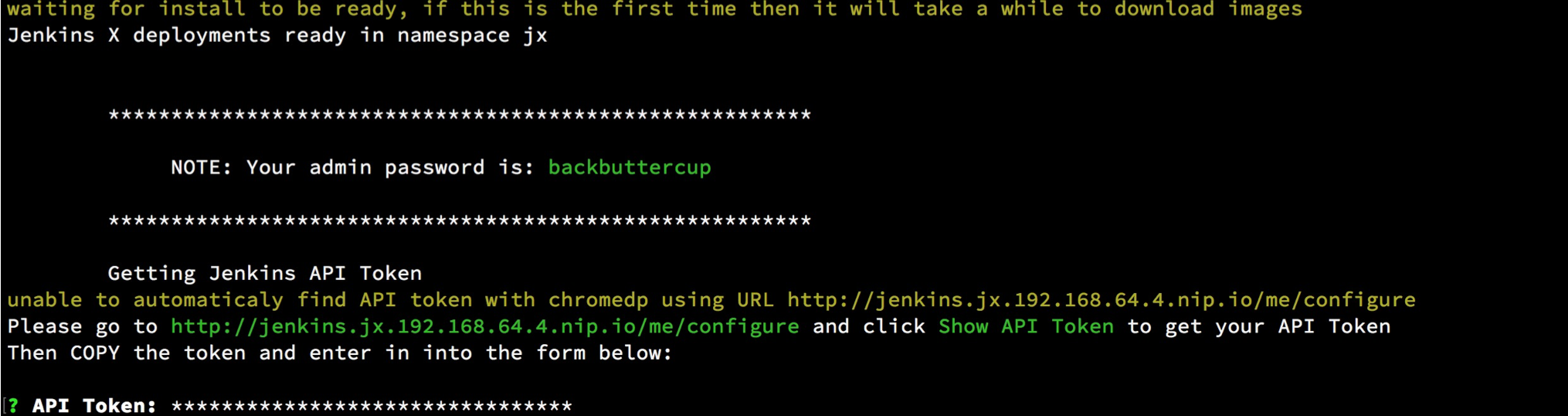
等待一段时间,jx 会在 k8s 上部署包括 jenkins、nexus等应用,部署完成会出现
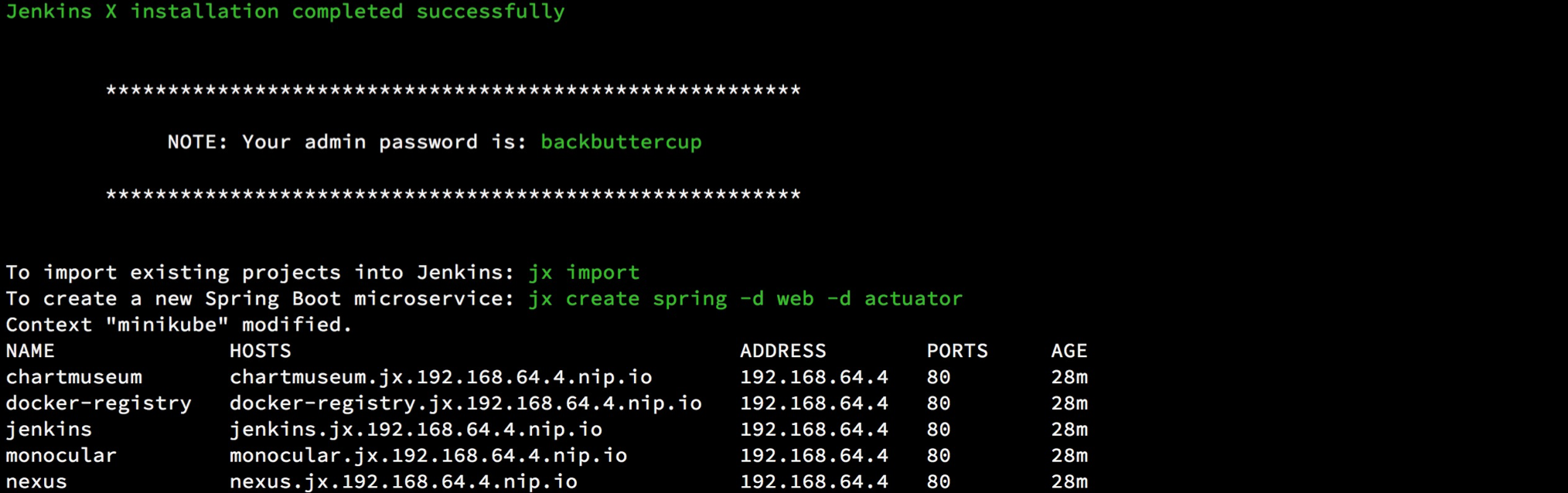
使用
这里可以参考官方 demo: demonstration of Jenkins X
感受
在使用 Jenkins X 的时候,感觉还是有些坑的,我简单地罗列了一下:
- 确保你的 kubectl 的版本要 >= 1.6
- 对于较高版本的 macOS,需要升级 homebrew
- 在使用 minikube delete 的时候遇到了一下系统权限的问题,可能是 Bug
其实 jx 是简单地整合了 CI & CD 在云原生应用上的工具链,包括 Helm 、k8s、Draft,对于用户而言,隐藏了很多繁琐的配置。但从目前的版本上看,jx才刚刚起步,我们可以看到在其官方的 roadmap 中,关于 Tools、Git Providers、Issue Trackers 方面还有很多路要走,这肯定需要开源社区的努力,另外在企业定制化方面可能也需要有更多的思考,这是一个通用的工具链不得不面对的问题。
关于 jx 的未来,我们拭目以待。